Projection models considered
For this project I considered two types of machine learning models. ANN and RFR. Below is a list of a few reasons why these were chosen for consideration.
ANN
- Artificial Neural Network
- Can capture complex, non-linear relationships
- Can automatically learn relevant features from input environmental data, reducing the need for manual feature engineering
- Highly flexible models and can adapt to different types of data
- Can produce models with high predictive accuracy
- Can effectively handle missing or incomplete data
- Generalizes well
RFR
- Random Forest Regression
- Is an ensemble learning method
- Can capture non-linear relationships
- Can efficiently handle high-dimensional datasets and is less sensitive to multicollinearity among predictors
- Difficult to overfit
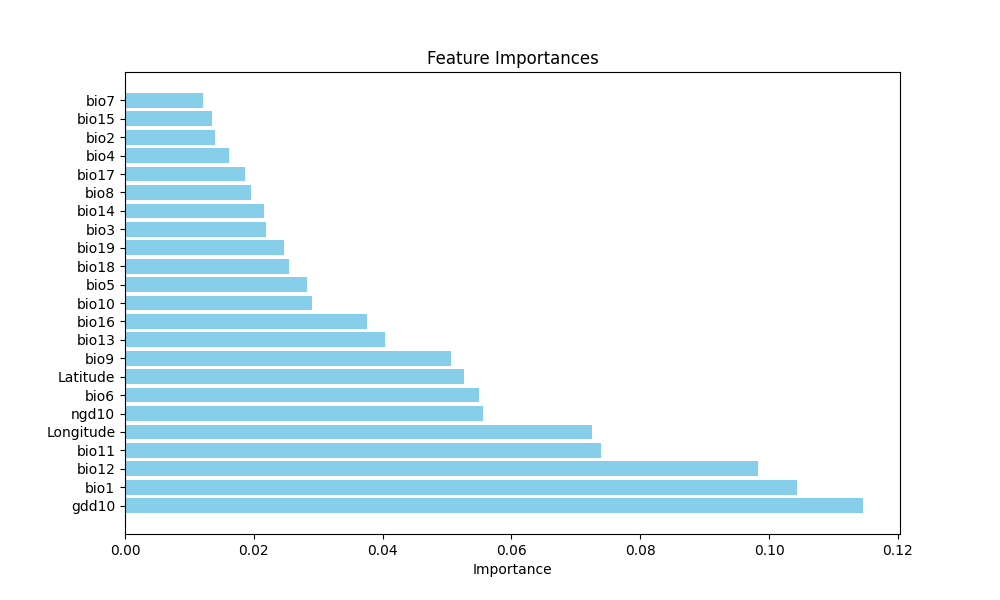
- Provides a measure of variable importance
- Relatively transparent and easier to interpret